Servicio Ollama + OpenWebUI
Ollama
En el servidor se ha montado un servicio de ollama, para poder correr modelos de AI o LLM`s en local. Para ello aprovecho y uso mi grafica RTX 3060 Ti.
Aqui dejo el docker compose:
version: "3.9"
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
# HABILITA GPU NVIDIA (CUDA)
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
environment:
- OLLAMA_NUM_GPU=1
- OLLAMA_KEEP_ALIVE=24h
volumes:
- ./ollama:/root/.ollama
ports:
- "11434:11434"
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
environment:
- OLLAMA_BASE_URL=http://192.168.1.20:11434
- WEBUI_NAME=Ollama Server
- ENABLE_SIGNUP=true
volumes:
- ./webui:/app/backend/data
ports:
- "3000:8080"
depends_on:
- ollama
En el ya esta la configuracion para poder usar la tarjeta grafica, pero sera necesario instalar CUDA en el servidor para que ollama pueda detectar la tarjeta grafica.
Proxy Inverso
Hay una configuracion especial en el proxy inverso del servicio de OpenWebUI para poder usar la misma url tanto para la parte grafica como para poder usar la directamente la api de Ollama desde aqui.
set $auth_ok 0;
if ($http_authorization = "Bearer xxxxx") {
set $auth_ok 1;
}
if ($auth_ok = 0) {
return 401;
}
rewrite ^/api_v1/(.*)$ /api/$1 break;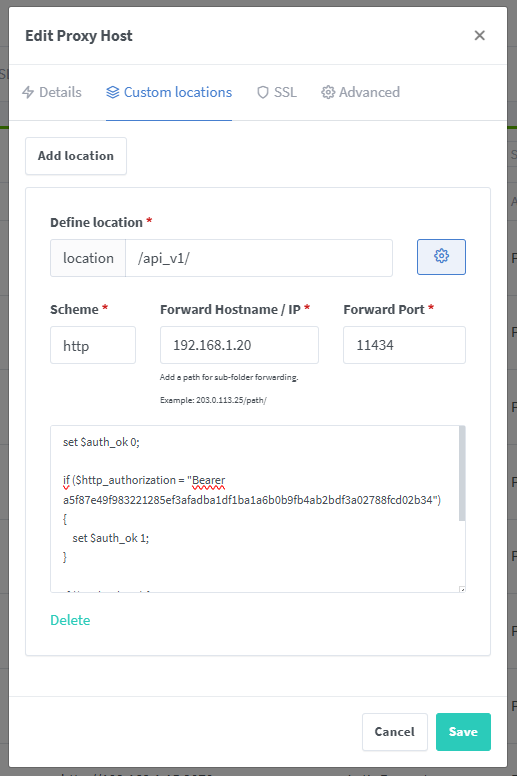
Asi desde la url https://ai.yeisonhomelab.xyz se accede al servicio de OpenWebUI y desde https://ai.yeisonhomelab.xyz/api_v1/ se accede a la api interna de Ollama. Aparte de esto, se ha configurado para que a la hora de acceder a la api se necesite un token de autenticacion.
POST /api_v1/generate HTTP/1.1
Authorization: Bearer xxxxxxxx
Content-Type: application/json
Host: ai.yeisonhomelab.xyz
Content-Length: 70
{
"model": "llama3.1:8b",
"prompt": "Que dia nacio Barack Obama"
}